In my previous post I described how AOM helped us build an agile development pipeline and increase the frequency, and more importantly the quality of our deliveries. This time I will describe how we harnessed AOM to revolutionize our architecture from legacy RDBMS to Big-Data.
As a provider of real-time marketing solutions to Tier-1 Telcos, the Pontis platform should handle massive data volumes –billions of mobile subscriber events that need to be processed and analyzed every day.
In our efforts to scale up our solution to handle the rapid growth of data, we quickly discovered that HW and licensing costs increase super-linearly with scale. The unreasonable costs made us realize we had no choice but to switch to Big Data architecture to be able to achieve a factor of 5-10 decrease in costs compared to our ‘classic’ architecture.
Initially – like any R&D group I guess – we were reluctant to change. We offered many logical reasons. For one, we knew from others that moving to Big Data could be a long and painful process. It would involve re-writing from scratch, training all R&D engineers, building a new infrastructure and many more painful and time-consuming tasks. Such a transformation could easily take 2-3 years or longer. And after all the effort was done, in order to support existing customers, we would end up with two product lines: the legacy platform and the new, Big Data product. This would mean two R&D teams and a never-ending compatibility headache.
AOM to the rescue
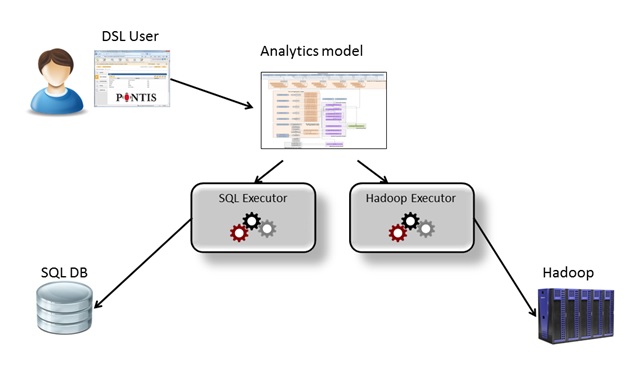
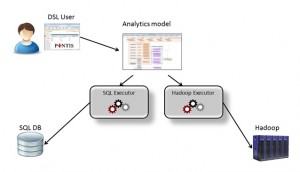
It then hit us. Our AOM development environment can come to the rescue. In this approach, business logic is written in Domain Specific Languages (DSLs) and is agnostic to execution technology. The model is platform-independent and handles the business-logic. Execution is done by thin engines that run the business-logic over the underlying technology platform. The DSL user defines the business-logic using abstract language that may have several execution engines for different platforms.
The move to Big Data, then, could be much easier. The total separation between the business logic and infrastructure layers reduces the need for overlapping knowledge between teams. We would not need to maintain separate product lines to support different technology platforms. Instead, we could build an Analytics-DSL that has execution engines for both platforms. We had to start by reverse engineering our existing Analytical application into an AOM DSL as it was originally developed in SQL.
True, we still had to obtain Big Data expertise. But we did not have to train all or even most of our team. Our infrastructure team mastered the necessary technologies, while the rest of R&D continued with their regular tasks.
Today, less than a year since we started our journey, we are in the certification stage and about to go live with our Big Data solution in a few weeks.